Can I help you find something?
(a very long "about page" for the library-browsing application haystacks)

I’m often haunted by the last scene in the Raiders of the Lost Ark where we watch an anonymous worker box up the ark of the covenant and file it into a storage facility. I saw this movie when I was eleven, and I still think of this scene surprisingly often, far more often than I recall the scene where the ark melts a Nazi's face off. On the one hand, this storage facility holds out a promise: what else is out there in the archives waiting to be found? The image helps feed a little reservoir of messianic faith that I draw on whenever I’m feeling particularly insignificant. Who knows when a project will find its destined reader, will be opened and proceed to melt some faces.
On the other hand, the more obvious interpretation of this scene is that no-one will see the ark of the covenant ever again. They might as well be lowering it into the bottom of the ocean. Paradoxically, I also think of this scene in post-partum project moments, boxing up an exhibition: I imagine it sinking into a storage facility like a piece of garbage into a landfill. Will the right audience ever find it?
Getting the right information to the right person is the central ambition of libraries. Carl Sagan reckons that you are likely to read no more than about 2,000 books in your adult life. Harvard University's library, the largest private library system in the world, has roughly 18 million items. The ratio works out to be less than a 10,000th of a percent. This kind of number gives me what I call the “bad ark” feeling. Once an item gets lost in the system, how will we ever find it again?
Today, if you have access to a computer connected to the internet, searching for something you already know you want has never been easier. Basing our own reading habits on those of our peers is possible in ways never before imagined. But as our tools for searching and recommending have sharpened, our tools for browsing have dulled. The pathways between popular texts are practically paved, but the hinterlands of obscure resources are more crowded over with brush then ever before.
This essay is about some human experiments in sorting books and making them findable. It is an argument for the value of browsing, and a survey of some different ways that libraries can make browsing into a meaningful experiences. You can also think of it as a long "about" page: an explanation for some of the design decisions we made in the library-browsing application "Haystacks." You can search and browse with haystacks here
THE SHELF AS USER INTERFACE
For many, the experience of searching for books begins and ends with Amazon.com. You enter text into a box, and Amazon will show you their most popular items that match that text. Once you look at an individual thing, you'll see other things that people who have looked at that thing have also looked at.
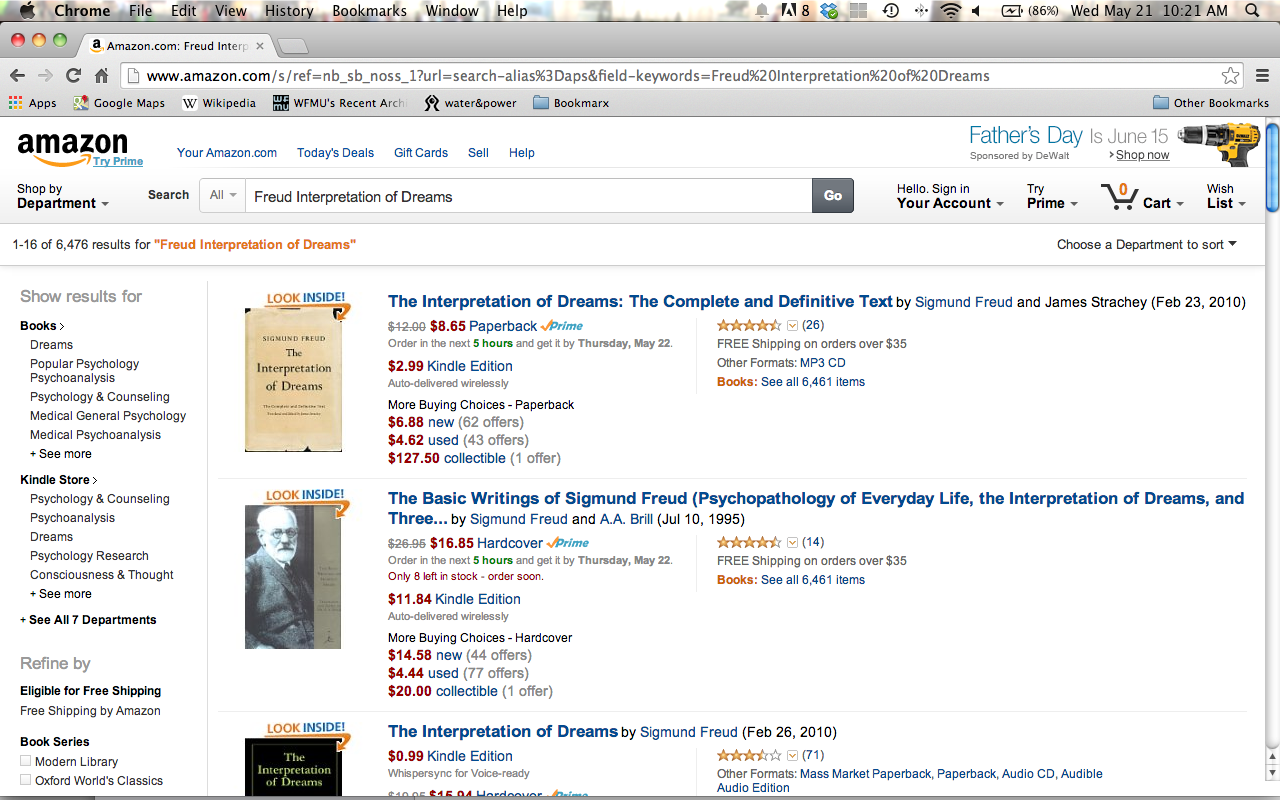
By design, this kind of search pushes your interests towards basins of attraction. That which is obscure will become more obscure, while that which is popular grows more popular. A similar dynamic occurs in a Google search. In either of these cases your “view” will be highly constrained. At any one time, you're likely to see 6 or 8 possible answers to your query. Most likely you will browse, if you browse at all, by falling down a chain of links, from one thing-that-other-people-searched-for to another.
At a bookstore, your ability to browse is a bit improved, but not by much. If you make it beyond the 15 or 20 titles that have been given prime placement by bookstore staff (or a marketing team), you'll move to a specific section. This section name will likely be taken from one of 42 top-level categories created in 1975 by a trade organization of book manufacturers, including "Poetry," “Antiques and Collectibles,” and “True Crime.” Bookstores opt in to whichever of these categories they find useful; most bookstores use only a tiny fraction of them. If you go into the store looking for Guns, Germs, and Steel, for instance, you may be looking in a section that is as specific as “World History” or as general as “non-fiction.”
Within a given section, books are organized alphabetically. Alphabetical organization vastly aids precise searching (think of your spice rack, or a dictionary) but scrambles any deeper sense of coherence.
Despite the limits of bookstore browsing, a bookshelf is a much denser user interface than a computer screen. In a single view you can take in hundreds of books. A glance in any direction can supplement the view with hundreds more. You can make instant assessments about a book's length, its dimensions, or its likelihood to contain pictures. Being able to see related books at a glance is a major draw of “open stack” library research.

DUI
Most libraries in the United States use the Dewey Decimal system. If you grew up in the United States, you've heard of it. Its inventor, born Melville Dewey, was so obsessed with standardization that he championed a new form of spelling that eliminated redundant letters. (At one point, he spelled his name “Melvil Dui.”)
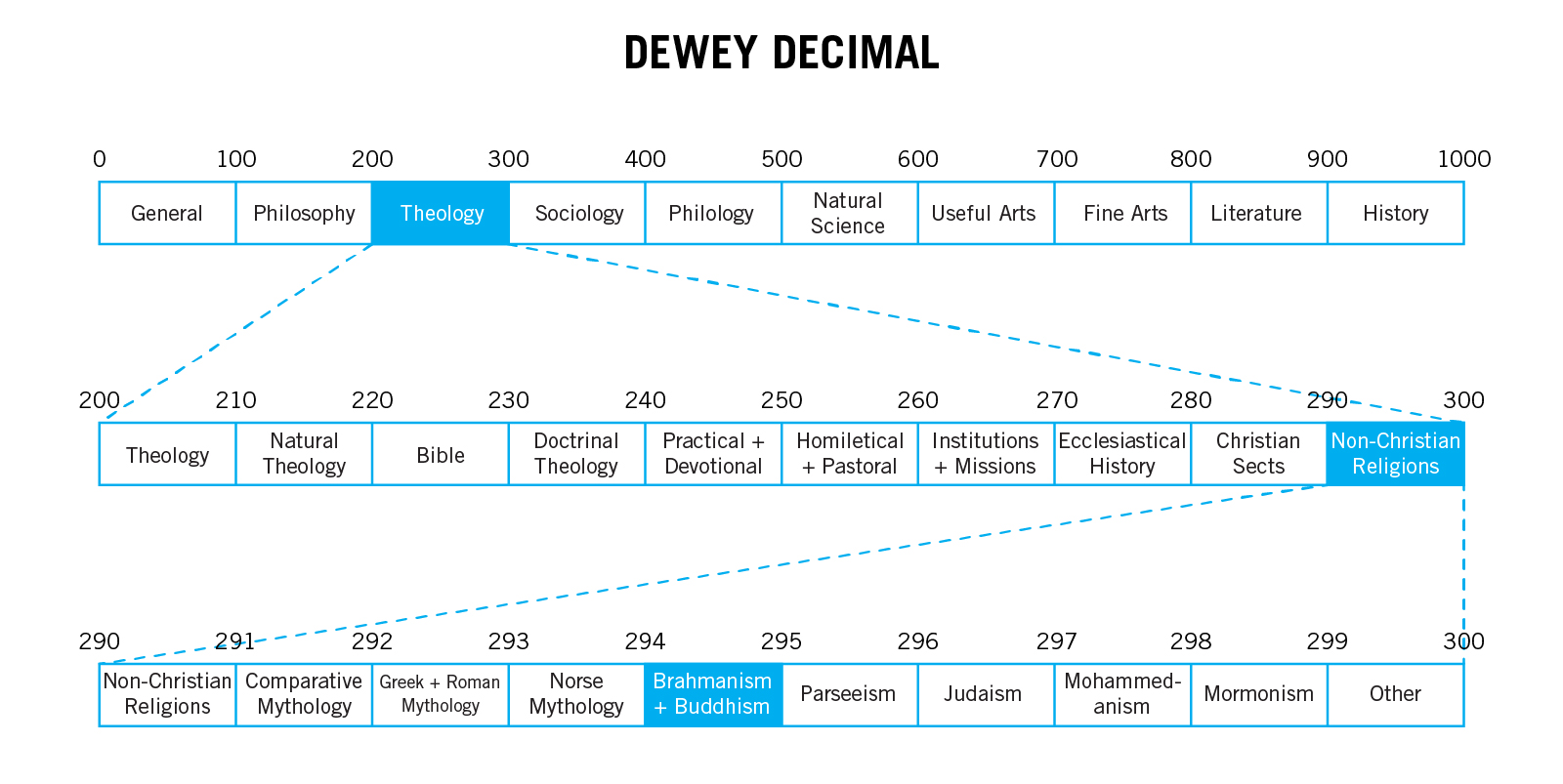
The genius of Dewey’s system is that its decimals allow subjects to nest within one another. The system uses 10 top-level categories, and splits each of these into ten more. The process can go on indefinitely, forming a completely hierarchical tree. When it was first published, the system fit on a 4-page pamphlet. It now spans four volumes and holds over 100,000 defined categories, and can be extended infinitely.
294.361
Gurus--Buddhist--role and function
This system has two clear advantages. First, the final resulting number gives librarians a definite location to shelve a given book; and, second, the system can easily accommodate growth. This is a vast improvement over the systems that preceded Dewey’s where, for instance, books were numbered and stored in order of their acquisition. In a system like Dewey’s the library can grow, while books stay in the same relative location to other books in their classification. In this scheme, when you arrive at the book you are looking for, your attention can flicker across the shelf, and a chance to discover something unanticipated opens up. The Dewey Decimal system is a hierarchical system for ordering a series based on a book's “aboutness.”
Still, the downsides of a system like this are many. Most obviously, it requires that a book be given a single location and classified according to a single determination of “aboutness.” As the Indian librarian Ranganathan pointed out as early as 1890, the idea that a book is only “about” one thing is empirically false. Moreover, every book can be placed in at least two locations, one based on its subject and another based on its publication date.
The second major disadvantage of that the Dewey Decimal system is that it is not an intuitive classification. Unlike Google or the alphabetical organization favored by bookstores, Dewey requires prior knowledge about the system in order to use it. If you are not a professional librarian or a very bookish middle school student, you will almost certainly not be able to head directly to the stacks of a library and find what you are looking for. Instead, you must use an intermediary, like a librarian or an online card catalog.
The deficits of this kind of universal, hierarchical system get sharper when we look at the other most popular system for organizing a library (and the one currently used by Harvard). This is the Library of Congress Classification system. The LCC works quite similarly to the Dewey system Decimal system, but it is far more extensive. It is made up of two components: the Library of Congress Subject Headings and Call Numbers. The Subject Headings are what's known as a "precoordinate controlled vocabulary". “Controlled” means that it tries to consolidate terminology (only using “automobile” and not “cars,” for example, and referring seekers of “cars” to the category “automobiles” instead). “Precoordinate” means that these resources are grouped together by a librarian, and then classified in an ever narrowing hierarchy that provides context for a single term — e.g. “Social sciences — Economic theory — General works — Recent, 1843/1876- — English and American” The full subject heading is not just the collection of tags, but the tags in a specific order.
A book can have as many subject headings as the library cataloger sees fit, but they must be from a pre-set list approved by the Library of Congress. After a cataloger assigns Subject Headings to a book, they will give the book a Call Number that corresponds with the subject heading that the cataloger considers to be the book's “primary” subject. The Subject Headings and Call Numbers are not universal. Different librarians could assign the same book different Call Numbers and Subject Headings depending on their training, and their assessment of the library's needs. While the Dewey system tops out at about 100,000 categories, the Library of Congress classification record set holds more then 633,000. The index takes up a full standard library shelf. Nor it is a free public resource. An electronic version of the record set will run you $4,000.
From the standpoint of formal logic, today's Library of Congress Call Number and Subject Heading systems are a mess. The full Call Number is usually (but not always!) made up of two letters and then a number between 0 and 9999. Unlike the Dewey system, they are not organized by thousands or hundreds: the categories can split at any point along the integer field. This results in a lumpy, unpredictable system that provides few clues for users about what to expect.
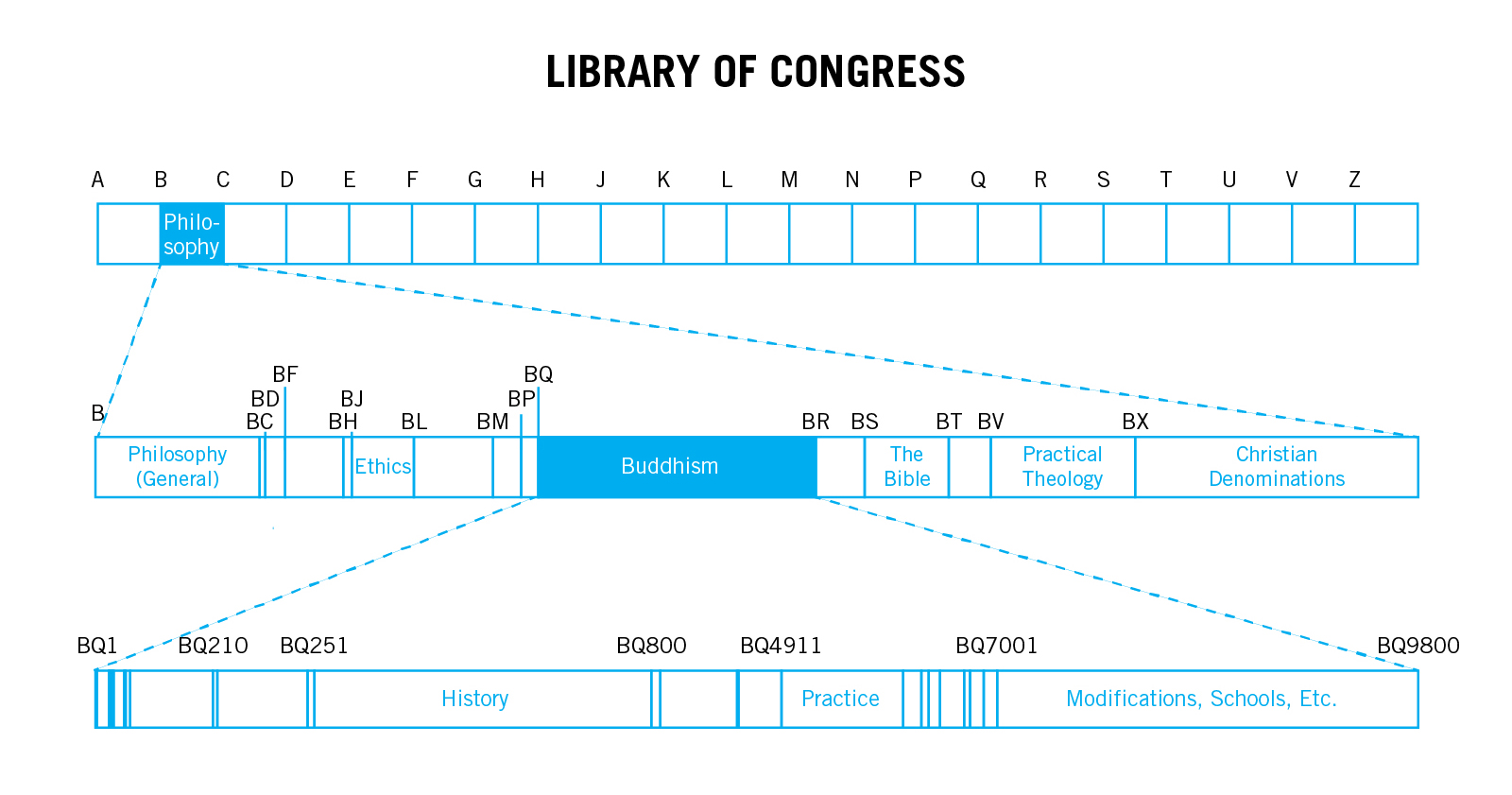
Though the LCC’s vocabulary is controlled, it doesn't follow a strict order from topic to topic. It is as hacked, retrofitted and jury rigged as a 19th century street grid or sewer system. The 21 top-level categories, designed for use by members of congress 200 years ago, are each given a letter of the alphabet. “Naval Science” and “Military Science” each get their own letter, whereas “World history and history of Europe, Asia, Africa, Australia, New Zealand, etc.” are shoehorned together under G. All of “Philosophy. Psychology. Religion” live together under the letter B. As you might expect from a system that has been maintained since the 19th century, some categorizations make little intuitive sense by by today's standards. For instance, you'll find “Gay rights movement” at the bottom of a subject chain that goes “Social sciences>The Family. Marriage. Woman>Human sexuality. Sex>Sexual minorities>Homosexuality. Lesbianism>Gay rights movement. Gay liberation movement. Homophile movement Gender.” Similarly awkward categorizations happen in every branch of knowledge that you can imagine. Activist librarians have lobbied for terminology changes (“Negro” was only changed to “African American” in 1996) or the addition of controversial branches, like “intifada.” A classification system like the Library of Congress Subject Headings (LCSH) clearly privileges certain ways of looking at the expense of others. You couldn't ask for a clearer embodiment of Knowledge and Power intersecting.
EXPRESSIVE STACKS
Systems like like the LCSH and Dewey Decimal are unwieldy, proprietary, complicated, and biased. Digital technology has in many ways "solved" most of the problems that these systems were created to address. Today, information no longer needs to have a single universally appropriate classification. This basic problem, sorting discrete pieces of information (music, photographs, texts) so that you can find them later, is less and less a real-life limitation of data. Digital information no longer needs to have a single physical location. A book no longer has to be “sociology” or “history”: it can be both simultaneously, called up with either term. David Weinberger writes about this persuasively and extensively in his book Everything is Miscellaneous.
One of the big ideas in data-access and classification of the 2000s was the project of “folksonomy”: a crowd-sourced method of relating things to each other that bypasses professional catalogers and allows items to accrue “tags.” No longer would you have to use a single centralized logic to find what you were looking for. If you need something that relates to magnesium, just type “magnesium” into your search engine, no need to go digging through “earth/elements/minerals/m.” Folksonomy, de-professionalizes categorization. No longer would we need professional gatekeepers to sort and label a collection's holdings. The crowd could classify and organize, building tag libraries that no professional library staff could rival.
“Finding” material by subject or keyword has become so much easier and commonplace. Anyone who has used google has a pretty good grasp on the process. As a result Library users expectations have changed. Encountering the arcana of a call number and subject heading system is cause for bewilderment. These changes in patrons’ expectation have led some librarians have to abandon the old hierarchies. In 1997, the Maricopa library system in Gilbert County, Arizona made national news by dropping the Dewey Decimal system. Instead, Maricopa libraries organize their books like a bookstore, using the categories developed by booksellers. The spines of their books are marked with tags that read in plain English (“History”) instead of “335.322 H 45.” Maricopa contends that this is a step towards making the library a more relevant place for its patrons. If you are looking for an easily categorized book, you no longer need to use an intermediary like a card catalog or a librarian, you just walk over to the place you'd find it in a bookstore and pluck it out of the shelf. Since Maricopa, dozens of libraries have followed suit. Detractors call this the “Google-ization” or Barnes-and-Nobles-ization” of the library. Nuanced categories developed by librarians are replaced by very general categories developed by booksellers. Finding a specific book is much easier, but looking for books in a broader category like "19th Century Chinese Poetry" becomes much harder if not impossible.
Cataloging all human knowledge in a definitive order is a quixotic project at best. No book is about just one thing. But one of the residual aspects of a classification system like the Dewey Decimal or the Library of Congress Subject Headings is that they organize knowledge into a structure that reflects intuitive cultural ideas about how topics are related. When you browse those stacks, the evidence of a human intelligence is evident. You may disagree with the logic of classification, but you are likely to find something interesting next to the thing that you were looking for.
We no longer need systems like the Dewey Decimal system to keep track of materials, but we don’t have to think of them as simply obsolete. Just as photography freed painting from having to do the work of representation, information technology has perhaps liberated shelf orders to become expressive. Below are a few examples of what I call Expressive Stacks.
1. The Prelinger Library
Rick and Megan Prelinger operate The Prelinger Library, a 50,000 item private collection that is open to the public. They organize their books according to a flamboyantly subjective, discursive order. One wall of shelves is organized like a map of the United States (books about Seattle in the upper left; books about Florida are in the lower right corner). Another bank of shelves moves like the film Powers of Ten from the microscopic (dust mites, mitosis) to the galactic (Solar Systems, Supernovas). If you need something specific, you can still use a card catalog or ask a librarian, but at its heart the Prelinger is (to use their term) a “serendipity” library. Browsing these shelves is like rummaging around in the Prelingers’ mind. The categorization and sorting is a great part of the collection's value. (Read Megan Prelinger's Description of the Sort Order)

2. Metis
Children make up another specialized library audience. Most school and public libraries use the Dewey Decimal system. The librarians of the Ethical Culture school in New York took it upon themselves to revise their shelf categories in ways they felt better facilitated their students' instincts and interests. The system uses just 26 decidedly non-orthogonal categories like “facts," "concepts,” "USA," and “scary.” These categories would make an epistemologist cringe but Metis's supporters content that these categories facilitate meaningful browsing for their users. Children who are looking for scary material, or for books about machines, know just where to go. Metis and Maricopa are both responses to the idea that library science's traditional categories no longer “cleave at the joints” for their specific publics. Why use categories that make no sense to the library’s patrons?
3. Sitterwerk
What about a categorization that is ever changing? On the Swiss island of St. Gallen, the Sitterwerk foundry holds a 50,000 volume collection with no defined organization at all. The books are shelved on open stacks but patrons are allowed — encouraged, even — to browse through them and leave them in any order they like. Every book in the library is embedded with an RFID chip, and each night a little scanning robot traverses the library’s shelves, recording each book’s location. Librarians no longer worry about where a book is shelved and any title can be found using the library’s online card catalog, updated nightly. Patrons re-shelve the books however they like. Different researchers cluster their books of interest. Over time library patrons assemble an emergent order. As you stroll the shelves you see the tracks of every prior patron. It’s an intuitively appealing, poetic mix of high and low technology. Visit the website here. Andrea Davis, the Sitterwerk’s Artists in Residence put together this moving tribute to the Sitterwerk's robot librarian.
++++
Categorization systems have everything to do with scale. A system that works perfectly well for a personal library breaks down when it is applied to a larger collection and a larger community. Would the Sitterwerk’s organization system work for a library system with 16 million items, spread out across 73 libraries? It’s possible.
But the Library of Congress cataloging system is not necessarily as far from the idiosyncracies of the Sitterwerk or the Prelinger archives as you might think. The hacked-together, aspect of the LCSH turns out to be its great strength. Its problems are unfixable; too many decisions have been made downstream from the branching that gave Naval and Military science their own top-level categories. But it continues to work in its unscientific way because so many people have contributed to and elaborated their tiny piece of the “schedule.” The LCSH doesn't have a single author. It is the epitome of “by committee” design. Individuals who care deeply about their given subjects have each spent decades dividing and subdividing them in order to create meaningful research categories. Different branches work differently from others, because librarians who specialize in particle physics think of their categorical space differently than those who work with Russian literature. It is this very messy, non-universal kind of classification process that, against all odds, continues to put books that are of interest to you next to other books that are of interest to you when you look at the shelf of a library. Rather than seeing the LCSH as an imperfect universal system, then, we can see each instantiation of it as a perfect, subjective reflection of the complicated history of a particular place.
ShelfLife, Stackview, Haystacks

My colleague Jeff Goldenson, seeded the haystacks project (and several others) with a project he called “Stack View,” The elevator pitch: “Google street view for library stacks.” While an artist-in-residence at Teachers College Columbia University, he prototyped a browsing interface that emulated the ambulatory interface of open stacks. It used Google’s mapping technology to actually serve up images of library shelves that allowed one to pan and zoom across the shelves. This brought the physical stack order into the online space, as well as the expressive dimensions of each book's size, binding and spine typography. But it also suffered from all the limitations of the physical shelf. If a book was taken out or mis-shelved, or didn't exist at the time of capture, it would not make it into Stack View, either.
The next iteration of Jeff’s idea became StackLife, a fully functioning alternative to Harvard's Online Public Access Catalog. StackLife made a fully digital graphical representation of the library's holdings, including serials, DVDs, and books. StackLife’s interface is skeuomorphic, meaning that it is built around a metaphor from the physical world. Here, sach title is represented as a book spine. The height and width of each spine corresponds to the actual book’s height and page count. In addition, the view incorporates the circulation data that Harvard has been recording since 2002. Books are heatmapped by their usage: the more a book circulated, the bluer its spine. In real life, Harvard's collection is spread over 73 plus libraries. It would be impossible to see anything close to the complete holdings of any one subject area or call number range in any one physical place, but StackLife let’s a user pull together “shelves” using keyword searches. In this way, it vastly improves on the functionality of StackView, (though it does lose some of the tactile charm and contextual information of StackViews photo-representation).
Still, the “stack” is stuck in the tiny physical dimensions of the screen, only able to show a few dozen items at a time. Browsing is still a bit of a chore and the underlying logic of the keyword search is pretty opaque. It was at this point that Harvard asked me to create a series of visualizations that would give the “mile-high” perspective. They had the data, but what did it look like?
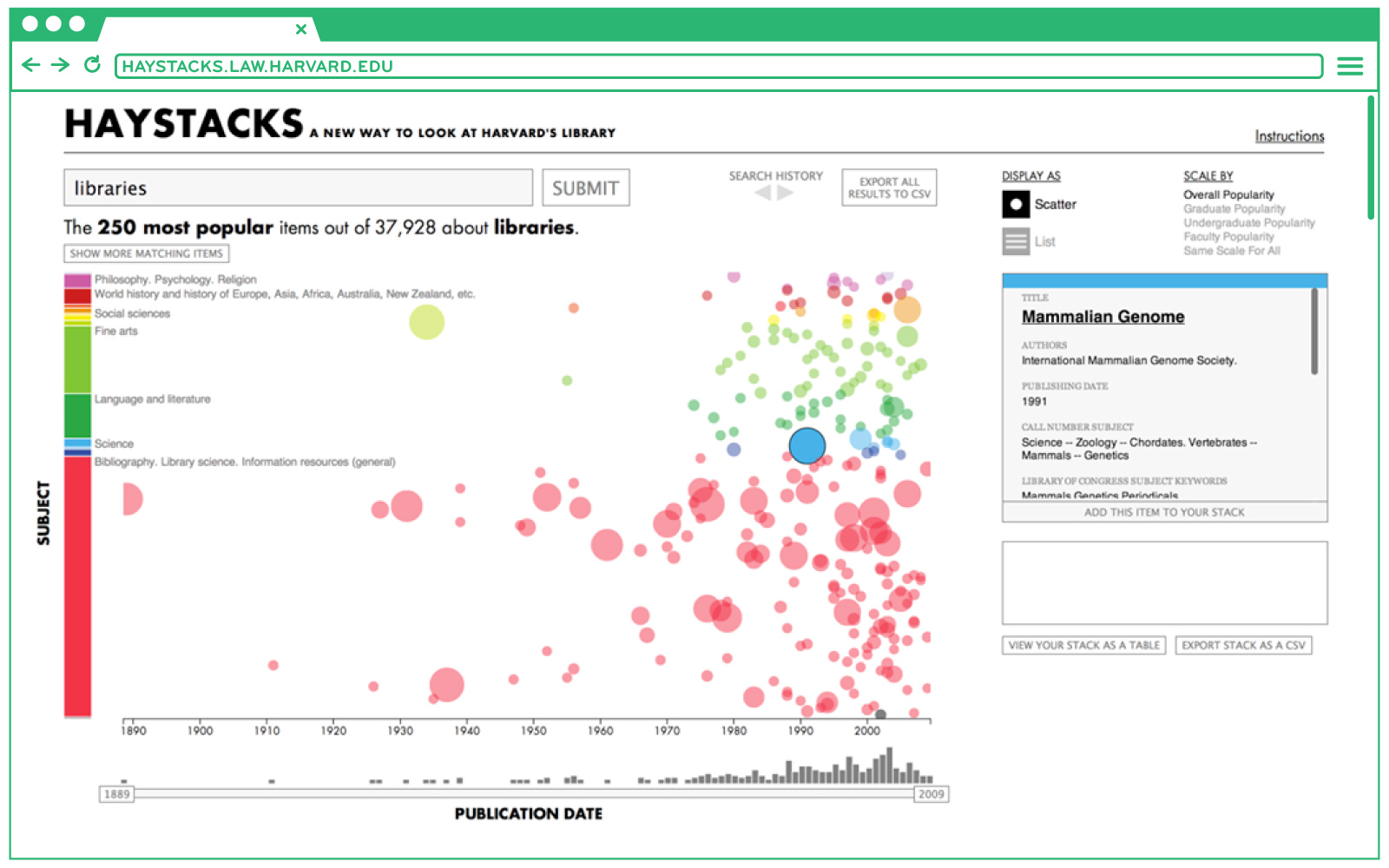
Play with it here: all books
here: Los Angeles
here: Workshops
or here: time travel
In this view, you call up a set of library items using a text window in the same way you might in any online card catalog. But here each item is represented by a colored dot. This is one of the oldest approaches to data visualization that we have: a scatter-plot. But it was immediately satisfying and useful, and it pointed out just how primitive most public library finding aids have remained. A typical card catalog brings up just a few resources, maybe 10 or 20 at a time, and doles out just a tiny bit of contextual information. In haystacks, when you bring up a search, we display up to 1,000 books at a time, each organized by call number on the y axis and date of publication on the x. The books are color-coded using the Library of Congress's top level categories. You can zoom into any area of the display and continue to zoom into whatever stretch of the catalog interests you. Moving through the card catalog becomes a mix of searching and browsing. You can filter the results by a specific keyword, but you can also add more titles based on the section of the catalog you’re looking at. You can see not only what’s right in front of you, but also what’s next to it, and what’s on the periphery. Our hope is that this suggests a different avenue for digital collection and classification. Rather than razing the 20th Century catalog like an old village street making way for the modern street grid, we can embellish what’s already there, making it richer and more navigable, and highlighting its existing value and charm.
Our hope is that by visualizing and automating this massive, flawed, and intricately detailed system of "aboutness" –the Library of Congress Subject Headings– haystacks can help you find that rare face-melting resource –some essential text that you didn't even know you were looking for.